Continuous Integration
Software Engineering
(for Intelligent Distributed Systems)
A.Y. 2025/2026
Giovanni Ciatto (reusing material made by Danilo Pianini)
Compiled on: 2026-07-05 — printable version
Continuous Integration
The practice of integrating code with a main development line continuously
Verifying that the build remains intact
- Requires build automation to be in place
- Requires testing to be in place
- Pivot point of the DevOps practices
- Historically introduced by the extreme programming (XP) community
- Now widespread in the larger DevOps community
What is integration in the first place?
-
Not just simply merging code from different branches/developers…
-
… but actually also building the software, with all its dependencies…
- restoring dependencies
- compiling
- linking
- packaging
-
… and testing the software
- all sorts of automated tests: unit, integration, system, etc.
- possibly, also deployment and release procedures
-
for the sake of checking that the software as a whole is still working despite the changes since the last release
-
possibly, doing further adjustments to the software code if necessary
- e.g., if the component is not working any more, or if the tests are failing, etc.
- here code may also include configuration files or build, test, or deployment scripts
The integration hell
- Traditional software development takes several months for “integrating” a couple of years of development
- The longer there is no integrated project, the higher the risk
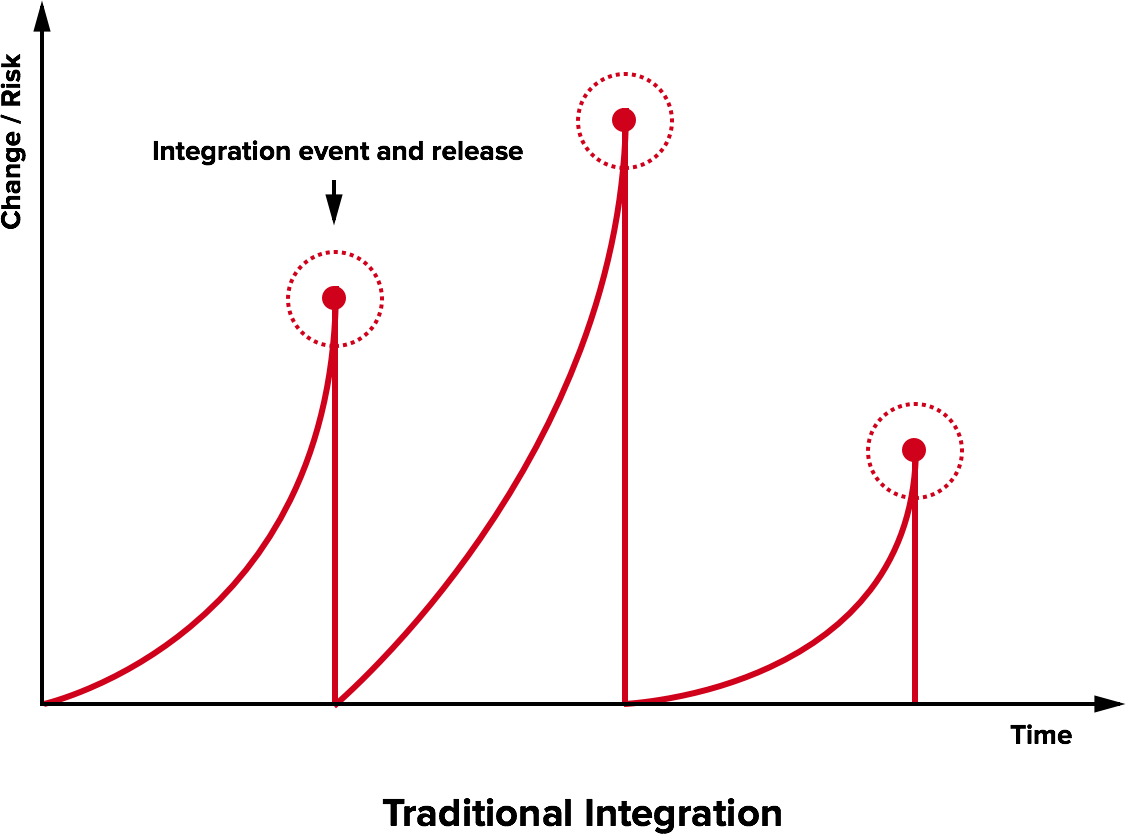 $\Rightarrow$
$\Rightarrow$

How to make the integration continuous?
-
Repeat the integration process as frequently as possible
- ideally, as frequently as every commit, in practice, as frequently as every push to GitHub
-
This implies running build, testing, and deployment processes very frequently as well
- which is only possible if the entire process is automated
- which is only possible if automatic tests are available, as well as build automation scripts, and automatic release/deployment scripts
- of course, retrospective adjustments are hard to automate, and should be done manually
- which is only possible if the entire process is automated
-
Do not rely on the assumption that developers will always remember to run these steps consistently before pushing
- they will not, and they will forget to do it at some point
- so we also need to automate the triggerig of the build, testing, and deployment processes
-
Once the entire process is automated, there are further benefits:
- integration issues can be spotted ASAP
- the process can be repeated on different platforms (e.g. different OSs, and different versions of Python)
- which is far more than what a developer can do on their own
- emails and notifications can be sent upon failures of the process
Continous integration concept
- The build process should be rich (comprehensive), fast, and automated
- And run on another machine (or VM) than the developer’s one
- this is to avoid the developer from being unable to work while the build is running
- but also to ensure that the software runs outside from the developer’s environment
- which increases the chances that the software will run on other machines as well
- to allow for testing the software onto many, controlled environments
- which in turns allows for giving compatibility guarantees to the customers/users

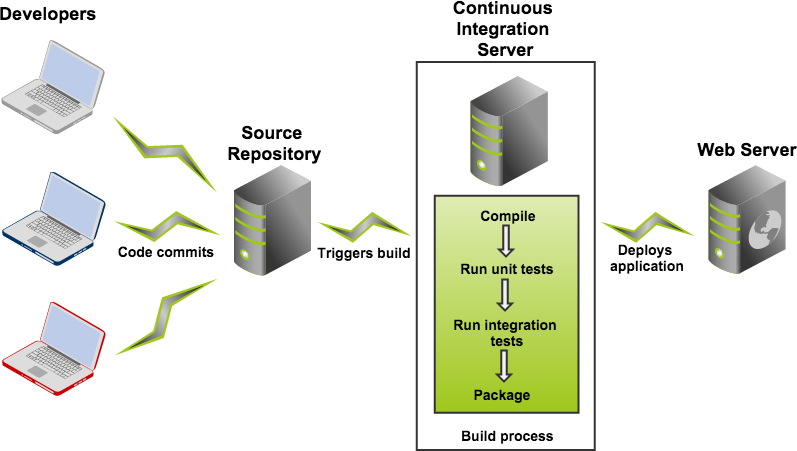
Continuous integration software
Software that promotes CI practices should:
- Provide clean environments for compilation/testing
- Provide a wide range of environments
- Matching the relevant specifications of the actual targets
- High degree of configurability
- Possibly, declarative configuration
- A notification system to alert about failures or issues
- Support for authentication and deployment to external services
Continuous integration software
Plenty of technologies on the market
- Circle CI
- Travis CI
- Werker
- done.io
- Codefresh
- Codeship
- Bitbucket Pipelines
- GitHub Actions
- GitLab CI/CD Pipelines
- JetBrains TeamCity
We will use GitHub Actions: GitHub integration, free for FOSS, multi-os OSs supported
Core concepts
Naming and organization is variable across different technological, but in general:
- One or more pipelines can be associated to events
- For instance, a new commit, an update to a pull request, or a timeout
- Every pipeline is composed of a sequence of operations
- Every operation could be composed of sequential or parallel sub-operations
- How many hierarchical levels are available depends on the specific platform
- GitHub Actions: workflow $\Rightarrow$ job $\Rightarrow$ step
- Travis CI: build $\Rightarrow$ stage $\Rightarrow$ job $\Rightarrow$ phase
- Execution happens in a fresh system (virtual machine or container)
- Often containers inside virtual machines
- The specific point of the hierarchy at which the VM/container is spawned depends on the CI platform
Pipeline design
In essence, designing a CI system is designing a software construction, verification, and delivery pipeline with the abstractions provided by the selected provider.
- Think of all the operations required starting from one or more blank VMs
- OS configuration
- Software installation
- Project checkout
- Compilation
- Testing
- Secrets configuration
- Delivery
- …
- Organize them in a dependency graph
- Model the graph with the provided CI tooling
Configuration can grow complex, and is usually stored in a YAML file
(but there are exceptions, JetBrains TeamCity uses a Kotlin DSL).
Pipeline design (abstract example)

- Rectangles represent operations
GitHub Actions (GHA): Structure
-
Workflows are groups of one or many jobs
- triggered by events such as: a developer pushing on the repository, a pull request being opened, a timeout, a manual trigger, etc.
- multiple workflows run in parallel, unless specified otherwise by whoever designed the workflows
-
Jobs is a sequential list of logical steps
- different jobs from the same workflow run in parallel, unless a dependency among them is explicitly declared
- in case of a dependency, the dependent job will run only after the dependency job is completed successfully
- steps of the same job run in the exact same order as they are defined in the job
- each job runs inside a fresh new Virtual Machine (VM), with a selectable OS
- most common development tools (e.g. Git, Python, Poetry, etc.) are pre-installed by default…
- but further may be installed if needed (e.g.
MySQL,PostgreSQL, etc.)
- the VM is destroyed after the job is completed
- users can see the logs of the job execution
- any relevant data produced by the job must be explicitly saved elsewhere (as part of the job), otherwise it will be lost
- [IMPORTANT] jobs can be configured to run multiple times with different OS/runtimes: this is the matrix execution strategy
- different jobs from the same workflow run in parallel, unless a dependency among them is explicitly declared
-
Steps is just executing a command in the shell of the job’s VM
- e.g. cloning the repository via
git - e.g. restoring Python dependencies via
poetry - e.g. running the tests via
unittest - e.g. releasing the software via
poetry - e.g. doing some automatic edit to the repository (such as updating the version number), then committing and pushing the change automatically
- e.g. cloning the repository via
GitHub Actions (practical example)

- Small rectangles represent steps
- Azure boxes represent jobs
- The whole is a workflow
GitHub Actions: Configuration
-
Workflows are configured in YAML files located in the default branch of the repository
- in the
.github/workflows/folder.
- in the
-
One configuration file $\Rightarrow$ one workflow
-
For security reasons, workflows may need to get manually activated in the Actions tab of the GitHub web interface.
- on a per-repository basis
GitHub Actions: Runners
- Executors of GitHub actions are called runners
- virtual machines (commonly hosted by GitHub)
- with the GitHub Actions runner application installed.
- virtual machines (commonly hosted by GitHub)
Note: the GitHub Actions application is open source and can be installed locally, creating “self-hosted runners”. Self-hosted and GitHub-hosted runners can work together.
-
Upon their creation, runners have a default environment
- which depends on their operating system
-
Documentation available at https://docs.github.com/en/actions/using-github-hosted-runners/about-github-hosted-runners#preinstalled-software
Convention over configuration
Several CI systems inherit the “convention over configuration” principle.
GitHub actions does not adhere to the principle: if left unconfigured, the runner does nothing (it does not even clone the repository locally).
- Probable reason: Actions is an all-round repository automation system for GitHub,
- not just a “plain” CI/CD pipeline
- $\Rightarrow$ it can react to many different events, not just changes to the git repository history
GHA: basic workflow structure
Minimal, simplified workflow structure:
# Mandatory workflow name
name: Workflow Name
on: # Events that trigger the workflow
jobs: # Jobs composing the workflow, each one will run on a different runner
Job-Name: # Every job must be named
# The type of runner executing the job, usually the OS
runs-on: runner-name
steps: # A list of commands, or "actions"
- # first step
- # second step
Another-Job: # This one runs in parallel with Job-Name
runs-on: '...'
steps: [ ... ]
Workflow minimal example
name: CI/CD
on:
push:
branches: [ main ]
jobs:
test:
runs-on: ubuntu-latest
name: Test on Linux
timeout-minutes: 45
steps:
- name: Checkout code
uses: actions/checkout@v4
- name: Restore Python dependencies
run: poetry install
- name: Test
shell: bash
run: poetry run python -m unittest discover -v -s tests
Consider check-and-deploy.yml file on the calculator repository for a more complete example
GHA Steps: run vs uses
-
run: run a command in the shell of the runner- e.g.
run: poetry install - e.g.
run: poetry run python -m unittest discover -v -s tests
- e.g.
-
uses: run a GitHub Actions’ action
What is a GHA action?
-
In the eyes of the GHA user: a reusable and parametric functionality which makes sense in the GHA ecosystem
-
In the eyes of the GHA developer: a GitHub repository the code to parametrise and reuse some functionality
Checking out the repository
By default, GitHub actions’ runners do not clone the repository
(this is because actions may, sometimes, not need to access the code, e.g., when automating issues, projects, etc.)
Cloning and checking out the repository is done via a dedicated action:
name: Example workflow
on:
push:
branches: [ main ]
jobs:
permissions:
contents: write # Give write (e.g. push) permissions to this Job (i.e. steps may perform changes to the repository it self)
Explore-GitHub-Actions:
- name: Check out repository code
uses: actions/checkout@v4
with:
fetch-depth: 0 # Fetch all history for all branches and tags
token: ${{ secrets.GITHUB_TOKEN }} # Use the GITHUB_TOKEN secret to clone, enabling future pushes in next steps
By default, only the last commit of the current branch is fetched by this action (shallow cloning has better performance)
- $\Rightarrow$ It may break operations that rely on the entire history!
- e.g., computing the next version number depending on the last tag in the Git history
- use
fetch-depth: 0to fetch the entire history
- If you plan to be able to push changes to the repository, you need to
- provide a token with write permissions, e.g.
token: ${{ secrets.GITHUB_TOKEN }}- secrets are explained a few slides later
- if you use the
GITHUB_TOKENsecret, you need to set thepermissionsfield towritefor thecontentspermission- this is because the default permission for the
GITHUB_TOKENsecret are read-only
- this is because the default permission for the
- provide a token with write permissions, e.g.
Writing outputs
Communication with the runner happens via workflow commands
The simplest way to create outputs for actions is to print on standard output a message in the form:
"{name}={value}"
and redirect it to the end of the file stored in the $GITHUB_OUTPUT environment variable:
echo "{name}={value}" >> $GITHUB_OUTPUT
name: Outputs
on: # ...
jobs:
Build:
runs-on: ubuntu-latest
steps:
- id: output-from-shell
run: python -c 'import random; print(f"dice={random.randint(1, 6)}")' >> $GITHUB_OUTPUT
- run: |
echo "The dice roll resulted in number ${{ steps.output-from-shell.outputs.dice }}"
Build matrix
Most software products are meant to be portable
- Across operating systems
- Across different frameworks and languages
- Across runtime configuration
A good continuous integration pipeline should test all the supported combinations*
- or a sample, if the performance is otherwise unbearable
The solution is the adoption of a build matrix
- Build variables and their allowed values are specified
- The CI integrator generates the cartesian product of the variable values, and launches a build for each!
- Note: there is no built-in feature to exclude some combination
- It must be done manually using
ifconditionals
- It must be done manually using
Build matrix in GHA
name: Workflow with Matrix
on: # ...
jobs:
test:
strategy:
fail-fast: false
matrix:
os:
- ubuntu-latest
- windows-latest
- macos-latest
python-version:
- '3.10'
- '3.11'
- '3.12'
runs-on: ${{ matrix.os }}
name: Test on Python ${{ matrix.python-version }}, on ${{ matrix.os }}
timeout-minutes: 45
steps:
- name: Setup Python
uses: actions/setup-python@v5
with:
python-version: ${{ matrix.python-version }}
- name: Install poetry
run: pip install poetry
- name: Checkout code
uses: actions/checkout@v4
- name: Restore Python dependencies
run: poetry install
- name: Test
shell: bash
run: poetry run python -m unittest discover -v -s tests
Private data and continuous integration
We would like the CI to be able to
- Sign our artifacts
- Delivery/Deploy our artifacts on remote targets
Both operations require private information to be shared
Of course, private data can’t be shared
- Attackers may steal the identity
- Attackers may compromise deployments
- In case of open projects, attackers may exploit pull requests!
- Fork your project (which has e.g. a secret environment variable)
- Print the value of the secret (e.g. with
printenv)
How to share a secret with the build environment?
Secrets
Secrets can be stored in GitHub at the repository or organization level.
GitHub Actions can access these secrets from the context:
- Using the
secrets.<secret name>context object - Access is allowed only for workflows generated by local events
- Namely, no secrets for pull requests
Secrets can be added from the web interface (for mice lovers), or via the GitHub CLI:
gh secret set TEST_PYPI_TOKEN -b "dhhfuidhfiudhfidnalnflkanjakl"
Stale builds
- Stuff works
- Nobody touches it for months
- Untouched stuff is now borked!
- Connected to the issue of build reproducibility
- The higher the build reproducibility, the higher its robustness
- The default runner configuration may change
- Some tools may become unavailable
- Some dependencies may get unavailable
The sooner the issue is known, the better
$\Rightarrow$ Automatically run the build every some time even if nobody touches the project
- How often? Depends on the project…
- Warning: GitHub Actions disables
cronCI jobs if there is no action on the repository, which makes the mechanism less useful
Additional checks and reportings
There exist a number of recommended services that provide additional QA and reports.
Non exhaustive list:
- Codecov.io
- Code coverage
- Supports Jacoco XML reports
- Nice data reporting system
- Sonarcloud
- Multiple measures, covering reliability, security, maintainability, duplication, complexity…
- Codacy
- Automated software QA for several languages
- Code Factor
- Automated software QA
High quality FLOSS checklist
The Linux Foundation Core Infrastructure Initiative created a checklist for high quality FLOSS.
CII Best Practices Badge Program https://bestpractices.coreinfrastructure.org/en
- Self-certification: no need for bureaucracy
- Provides a nice TODO list for a high quality product
- Releases a badge that can be added e.g. to the project homepage
Automated evolution
A full-fledged CI system allows reasonably safe automated evolution of software
At least, in terms of dependency updates
Assuming that you can effectively intercept issues, here is a possible workflow for automatic dependency updates:
- Check if there are new updates
- Apply the update in a new branch
- Open a pull request
- Verify if changes break anything
- If they do, manual intervention is required
- Merge
Automated evolution
Bots performing the aforementioned process for a variety of build systems exist.
They are usually integrated with the repository hosting provider
- Whitesource Renovate (Multiple)
- Also updates github actions and Gradle Catalogs
- Dependabot (Multiple)
- Gemnasium (Ruby)
- Greenkeeper (NPM)
Check your understanding (pt. 1)
- In your own words, what is continuous integration?
- In your own words, what is integration hell?
- In the context of continuous integration, what is a pipeline?
- What is GitHub Actions?
- In the context of continuous integration, provide an overview of the abstract pipeline design
- In the context of GitHub Actions, what is the difference among workflow, jobs, steps
- How would you design a GitHub Actions workflow for a Python project?
- In the context of GitHub Actions, what is a runner?
- What is YAML? What is the difference between YAML and JSON?
- In the context of GitHub Actions, what is a matrix?
- In the context of GitHub Actions, what is a secret?
Check your understanding (pt. 2)
- In the context of software engineering, what is integration? What is continuous integration?
- In the context of software engineering, what are the issues arising from infrequent integration/release events?
- In the context of software engineering, how to make integration continuous?
- What is GitHub Actions? What is its purpose? How does it work?
- In the context of GitHub Actions, what is the difference among workflow, jobs, steps
- In an ordinary Python project using Poetry for build automation and release on PyPi and
unittestfor automatic tests, how would you organize a continuous integration pipeline? (What operations should be performed in each run of the pipeline?)
Lecture is Over
Compiled on: 2026-07-05 — printable version